網(wǎng)頁爬蟲 - python 爬取網(wǎng)站 并解析非json內(nèi)容
問題描述
小弟剛學(xué)會獲得json的內(nèi)容,但今天爬的網(wǎng)站返回的并不是json內(nèi)容 并且會有一個隨機數(shù)的生成在每次請求鏈接的后面
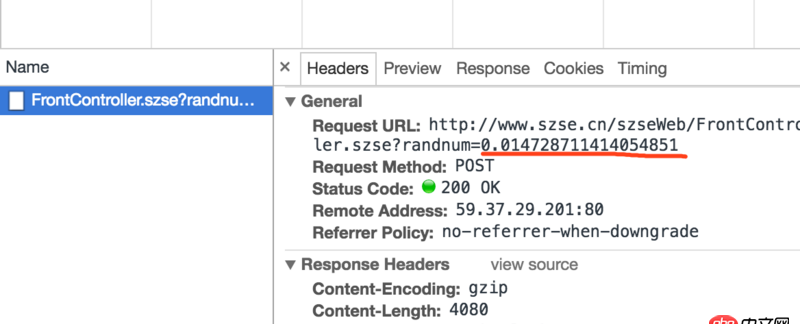
不知道會不會影響我要爬的內(nèi)容
需要獲得內(nèi)容是下圖中間的內(nèi)容
 網(wǎng)站鏈接 http://www.szse.cn/main/discl...
網(wǎng)站鏈接 http://www.szse.cn/main/discl...
我自己嘗試的代碼:
import requestsdir = ’/Users/S1Lence/Desktop/new_html/szse/許可類重組問詢函’headers = {’Host’: ’www.szse.cn’, ’Referer’: ’http://www.szse.cn/main/disclosure/jgxxgk/wxhj/’, ’User-Agent’: ’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36’ }payload= {’ACTIONID’: ’7’, ’AJAX’: ’AJAX-TRUE’, ’CATALOGID’: ’main_wxhj’, ’TABKEY’: ’tab1’, ’selecthjlb’: ’許可類重組問詢函’, ’tab1PAGENO’: ’1’, ’tab1PAGECOUNT’: ’7’, ’tab1RECORDCOUNT’: ’63’, ’REPORT_ACTION’: ’navigate’}res = requests.post(’http://www.szse.cn/szseWeb/FrontControllere’, data=payload)print(res.text)
輸出的內(nèi)容并不是我想要的 求解應(yīng)該怎么爬
問題解答
回答1:把他的header信息拷過來用。。
回答2:你post的url地址寫錯了,應(yīng)該是
http://www.szse.cn/szseWeb/FrontController.szse
相關(guān)文章:
1. 大家都用什么工具管理mysql數(shù)據(jù)庫?2. java - jdbc如何返回自動定義的bean3. mysql 可以從 TCP 連接但是不能從 socket 鏈接4. mysql函數(shù)unix_timestamp如何處理1970.1.1以前的數(shù)據(jù)?5. 怎么php怎么通過數(shù)組顯示sql查詢結(jié)果呢,查詢結(jié)果有多條,如圖。6. python - 請問這兩個地方是為什么呢?7. mysql的循環(huán)語句問題8. javascript - 按鈕鏈接到另一個網(wǎng)址 怎么通過百度統(tǒng)計計算按鈕的點擊數(shù)量9. 請教一個mysql去重取最新記錄10. mysql updtae追加數(shù)據(jù)sql語句

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備