網(wǎng)頁爬蟲 - python 爬蟲怎么處理json內(nèi)容
問題描述
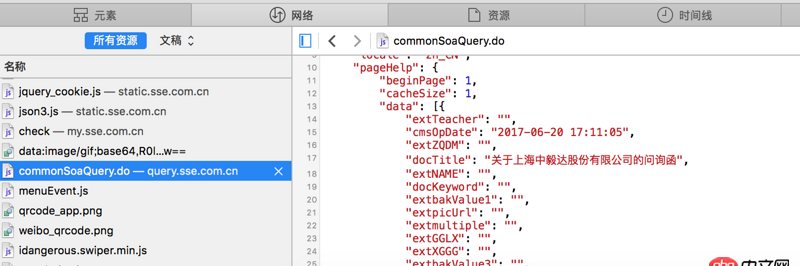
看不清的話 網(wǎng)站地址是http://www.sse.com.cn/disclos...紅字是我需要的內(nèi)容 但是我提取不出來求教怎么操作
問題解答
回答1:import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5’headers = { ’Referer’:’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’:’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’}r = requests.get(url, headers=headers)print r.json()[’result’]回答2:
import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382’session = requests.session()session.headers.update({ ’Referer’: ’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’})result = session.get(url).json()print result
相關(guān)文章:
1. mysql - 10g數(shù)據(jù)庫如何遷移2. php - 有關(guān)sql語句反向LIKE的處理3. 在視圖里面寫php原生標(biāo)簽不是要迫不得已的情況才寫嗎4. 獲取上次登錄ip的原理是啥?5. node.js - session怎么存到cookie,然后服務(wù)器重啟后還能獲取。數(shù)據(jù)庫不用mongodb或redis,數(shù)據(jù)庫是mysql6. 求救一下,用新版的phpstudy,數(shù)據(jù)庫過段時(shí)間會(huì)消失是什么情況?7. 為什么說非對象調(diào)用成員函數(shù)fetch()8. fetch_field_direct()報(bào)錯(cuò)9. 為什么點(diǎn)擊登陸沒反應(yīng)10. mysql多表聯(lián)合查詢優(yōu)化的問題
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備