文章詳情頁
python - scrapy運行爬蟲一打開就關閉了沒有爬取到數據是什么原因
瀏覽:78日期:2022-08-05 15:09:38
問題描述
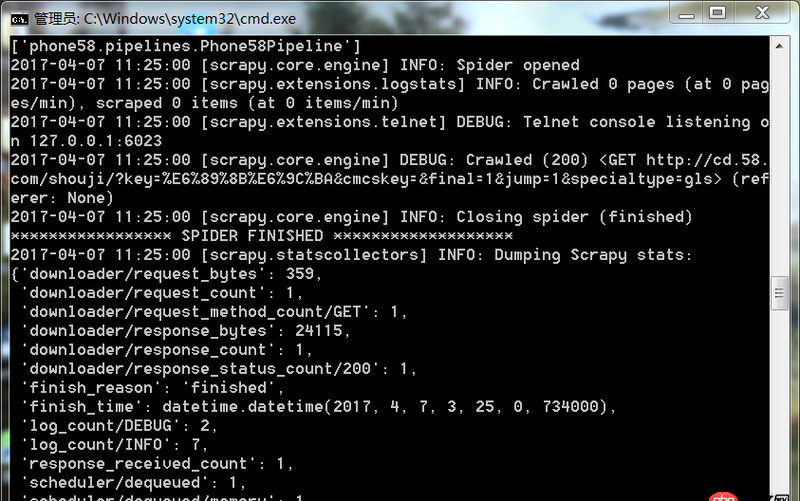
爬蟲運行遇到如此問題要怎么解決
問題解答
回答1:很可能是你的爬取規則出錯,也就是說你的spider代碼里面的xpath(或者其他解析工具)的規則錯誤。導致沒爬取到。你可以把網址print出來,看看是不是[]
相關文章:
1. html5 - css3scale和rotate同時使用轉換成matrix寫法該如何轉換?2. win10 python3.5 matplotlib使用報錯3. php多任務倒計時求助4. css - 如何把一個視圖放在左浮動定位的視圖的上面?5. javascript - jquery怎么讓a標簽跳轉后保持tab的樣式6. MySQL的聯合查詢[union]有什么實際的用處7. javascript - vue組件的重復調用8. javascript - 小demo:請教怎么做出類似于水滴不斷擴張的效果?9. python的正則怎么同時匹配兩個不同結果?10. javascript - axios請求回來的數據組件無法進行綁定渲染
排行榜
 網公網安備
網公網安備