python - BeautifulSoup指定lxml作為解析器報(bào)錯(cuò)?
問(wèn)題描述
環(huán)境:windows 10PyCharm 2016.3.2
遇到問(wèn)題:
剛開(kāi)始學(xué)python,想用BeautifulSoup解析網(wǎng)頁(yè),但出現(xiàn)報(bào)錯(cuò):
UserWarning: No parser was explicitly specified, so I’m using the best available HTML parser for this system ('lxml'). This usually isn’t a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.The code that caused this warning is on line 4 of the file C:/Users/excalibur/PycharmProjects/learn/getMyIP.py. To get rid of this warning, change code that looks like this: BeautifulSoup([your markup])to this: BeautifulSoup([your markup], 'lxml') markup_type=markup_type))
然后根據(jù)提示和官網(wǎng)的文檔加上:BeautifulSoup(markup, 'html.parser')
結(jié)果出現(xiàn)了這樣的報(bào)錯(cuò):

在Google搜了下,都是說(shuō)要導(dǎo)入路徑,但是在 Settings -> Project -> Project Interpreter 里是這樣的
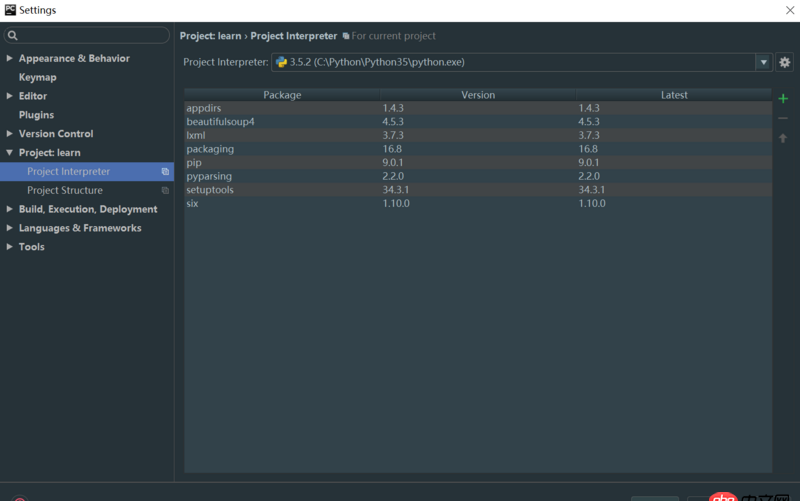
顯示BeautifulSoup已經(jīng)導(dǎo)入了
請(qǐng)問(wèn)我要怎么做才能解決這個(gè)問(wèn)題呢?
萬(wàn)分感謝!
問(wèn)題解答
回答1:找了其他人的代碼看,終于知道是什么問(wèn)題
并不是路徑的問(wèn)題,而是傳參的問(wèn)題
markup 其實(shí)是要解析的內(nèi)容,例如:
soup = BeautifulSoup('<html>data</html>', 'lxml')
或者
markup = '<html>data</html>'soup = BeautifulSoup(markup, 'lxml')
PS. 在文檔中沒(méi)有函數(shù)參數(shù)列表之類的,不知道是不是找的位置錯(cuò)了...
回答2:pip install lxml
相關(guān)文章:
1. MySQL主鍵沖突時(shí)的更新操作和替換操作在功能上有什么差別(如圖)2. 關(guān)于mysql聯(lián)合查詢一對(duì)多的顯示結(jié)果問(wèn)題3. python - scrapy url去重4. mysql在限制條件下篩選某列數(shù)據(jù)相同的值5. 數(shù)據(jù)庫(kù) - Mysql的存儲(chǔ)過(guò)程真的是個(gè)坑!求助下面的存儲(chǔ)過(guò)程哪里錯(cuò)啦,實(shí)在是找不到哪里的問(wèn)題了。6. 小白學(xué)python的問(wèn)題 關(guān)于%d和%s的區(qū)別7. python執(zhí)行cmd命令,怎么讓他執(zhí)行類似Ctrl+C效果將其結(jié)束命令?8. 實(shí)現(xiàn)bing搜索工具urlAPI提交9. python - Django有哪些成功項(xiàng)目?10. Python從URL中提取域名
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備