Python統(tǒng)計(jì)文本詞匯出現(xiàn)次數(shù)的實(shí)例代碼
問題描述
有時(shí)在遇到一個(gè)文本需要統(tǒng)計(jì)文本內(nèi)詞匯的次數(shù) 的時(shí)候 ,可以用一個(gè)簡單的python程序來實(shí)現(xiàn)。
解決方案
首先需要的是一個(gè)文本文件(.txt)格式(文本內(nèi)詞匯以空格分隔),因?yàn)樾枰氖且粋€(gè)程序,所以要考慮如何將文件打開而不是采用復(fù)制粘貼的方式。這時(shí)就要用到open()的方式來打開文檔,然后通過read()讀取其中內(nèi)容,再將詞匯作為key,出現(xiàn)次數(shù)作為values存入字典。
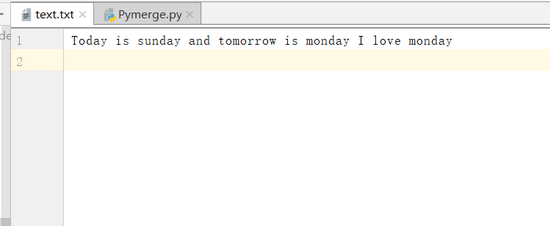
圖 1 txt文件內(nèi)容
再通過open和read函數(shù)來讀取文件:
open_file=open('text.txt')file_txt=open_file.read()
然后再創(chuàng)建一個(gè)空字典,將所有出現(xiàn)的每個(gè)詞匯作為key保存到字典中,對文本從開始到結(jié)束,循環(huán)處理每個(gè)詞匯,并將詞匯設(shè)置為一個(gè)字典的key,將其value設(shè)置為1,如果已經(jīng)存在該詞匯的key,說明該詞匯已經(jīng)使用過,就將value累積加1。
代碼示例:
def wordcount(readtxt):readlist = readtxt.split()dict1={}for every_world in readlist:if every_world in dict1:dict1[every_world] += 1else:dict1[every_world] = 1return dict1print(wordcount(file_txt))
這里加了def函數(shù)把該程序封裝成一個(gè)函數(shù)。 最后輸出得到詞匯出現(xiàn)的字典:
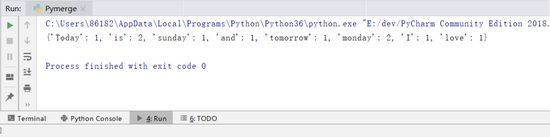
圖 2 形成字典
ps:下面看下python統(tǒng)計(jì)文本中每個(gè)單詞出現(xiàn)的次數(shù)
1.python統(tǒng)計(jì)文本中每個(gè)單詞出現(xiàn)的次數(shù):
#coding=utf-8__author__ = ’zcg’import collectionsimport oswith open(’abc.txt’) as file1:#打開文本文件 str1=file1.read().split(’ ’)#將文章按照空格劃分開print '原文本:n %s'% str1print 'n各單詞出現(xiàn)的次數(shù):n %s' % collections.Counter(str1)print collections.Counter(str1)[’a’]#以字典的形式存儲(chǔ),每個(gè)字符對應(yīng)的鍵值就是在文本中出現(xiàn)的次數(shù)
2.python編寫生成序列化:
__author__ = ’zcg’#endcoding utf-8import string,randomfield=string.letters+string.digitsdef getRandom(): return ''.join(random.sample(field,4))def concatenate(group): return '-'.join([getRandom() for i in range(group)])def generate(n): return [concatenate(4) for i in range(n)]if __name__ ==’__main__’: print generate(10)
3.遍歷excel表格中的所有數(shù)據(jù):
__author__ = ’Administrator’import xlrdworkbook = xlrd.open_workbook(’config.xlsx’)print 'There are {} sheets in the workbook'.format(workbook.nsheets)for booksheet in workbook.sheets(): for col in xrange(booksheet.ncols): for row in xrange(booksheet.nrows): value=booksheet.cell(row,col).value print value
其中xlrd需要百度下載導(dǎo)入這個(gè)模塊到python中
4.將表格中的數(shù)據(jù)整理成lua類型的一個(gè)格式
#coding=utf-8__author__ = ’zcg’#2017 9/26import xlrdfileOutput = open(’Configs.lua’,’w’)writeData='--@author:zcgnnn'workbook = xlrd.open_workbook(’config.xlsx’)print 'There are {} sheets in the workbook'.format(workbook.nsheets)for booksheet in workbook.sheets(): writeData = writeData+’AT’ +booksheet.name+’ ={n’ for col in xrange(booksheet.ncols): for row in xrange(booksheet.nrows): value = booksheet.cell(row,col).value if row ==0: writeData = writeData+’t’+’['’+value+’']’+’=’+’{’ else: writeData=writeData+’'’+str(booksheet.cell(row,col).value)+’', ’ else: writeData=writeData+’},n’ else: writeData=writeData+’}nn’else : fileOutput.write(writeData)fileOutput.close()
總結(jié)
到此這篇關(guān)于Python統(tǒng)計(jì)文本詞匯出現(xiàn)次數(shù)的實(shí)例代碼的文章就介紹到這了,更多相關(guān)Python統(tǒng)計(jì)文本詞匯出現(xiàn)次數(shù)內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Python從URL中提取域名2. php傳對應(yīng)的id值為什么傳不了啊有木有大神會(huì)的看我下方截圖3. python - scrapy url去重4. python - Flask寫的注冊頁面,當(dāng)注冊時(shí),如果填寫數(shù)據(jù)庫里有的相同數(shù)據(jù),就報(bào)錯(cuò)5. 關(guān)于mysql聯(lián)合查詢一對多的顯示結(jié)果問題6. 實(shí)現(xiàn)bing搜索工具urlAPI提交7. 數(shù)據(jù)庫 - Mysql的存儲(chǔ)過程真的是個(gè)坑!求助下面的存儲(chǔ)過程哪里錯(cuò)啦,實(shí)在是找不到哪里的問題了。8. python - oslo_config9. MySQL主鍵沖突時(shí)的更新操作和替換操作在功能上有什么差別(如圖)10. 小白學(xué)python的問題 關(guān)于%d和%s的區(qū)別

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備