獲取python運(yùn)行輸出的數(shù)據(jù)并解析存為dataFrame實(shí)例
在學(xué)習(xí)xg的 時(shí)候,想畫學(xué)習(xí)曲線,但無奈沒有沒有這個(gè) evals_result_
AttributeError: ’Booster’ object has no attribute ’evals_result_’
因?yàn)椴皇怯玫姆诸惼骰蛘呋貧w器,而且是使用的train而不是fit進(jìn)行訓(xùn)練的,看過源碼fit才有evals_result_這個(gè),導(dǎo)致訓(xùn)練后沒有這個(gè),但是又想獲取學(xué)習(xí)曲線,因此肯定還需要獲取訓(xùn)練數(shù)據(jù)。
運(yùn)行的結(jié)果 上面有數(shù)據(jù),于是就想自己解析屏幕的數(shù)據(jù)試一下,屏幕可以看到有我們迭代過程的數(shù)據(jù),因此想直接獲取屏幕上的數(shù)據(jù),思維比較low但是簡(jiǎn)單粗暴。
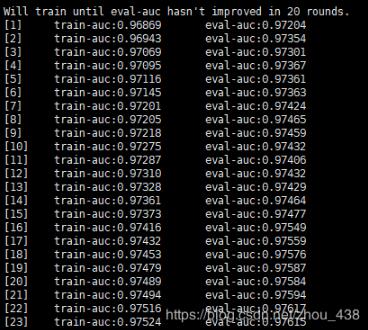
接下來分兩步完成:
1) 獲取屏幕數(shù)據(jù)
import subprocessimport pandas as pdtop_info = subprocess.Popen(['python', 'main.py'], stdout=subprocess.PIPE)out, err = top_info.communicate()out_info = out.decode(’unicode-escape’)lines=out_info.split(’n’)
注:這里的main.py就是自己之前執(zhí)行的python文件
2) 解析文件數(shù)據(jù):
ln=0lst=dict()for line in lines: if line.strip().startswith(’[{}] train-auc:’.format(ln)): if ln not in lst.keys(): lst.setdefault(ln, {}) tmp = line.split(’t’) t1=tmp[1].split(’:’) t2=tmp[2].split(’:’) if str(t1[0]) not in lst[ln].keys(): lst[ln].setdefault(str(t1[0]), 0) if str(t2[0]) not in lst[ln].keys(): lst[ln].setdefault(str(t2[0]), 0) lst[ln][str(t1[0])]=t1[1] lst[ln][str(t2[0])]=t2[1] ln+=1json_df=pd.DataFrame(pd.DataFrame(lst).values.T, index=pd.DataFrame(lst).columns, columns=pd.DataFrame(lst).index).reset_index()json_df.columns=[’numIter’,’eval-auc’,’train-auc’]print(json_df)
整體代碼:
import subprocessimport pandas as pdtop_info = subprocess.Popen(['python', 'main.py'], stdout=subprocess.PIPE)out, err = top_info.communicate()out_info = out.decode(’unicode-escape’)lines=out_info.split(’n’) ln=0lst=dict()for line in lines: if line.strip().startswith(’[{}] train-auc:’.format(ln)):if ln not in lst.keys(): lst.setdefault(ln, {})tmp = line.split(’t’)t1=tmp[1].split(’:’)t2=tmp[2].split(’:’)if str(t1[0]) not in lst[ln].keys(): lst[ln].setdefault(str(t1[0]), 0)if str(t2[0]) not in lst[ln].keys(): lst[ln].setdefault(str(t2[0]), 0)lst[ln][str(t1[0])]=t1[1]lst[ln][str(t2[0])]=t2[1]ln+=1json_df=pd.DataFrame(pd.DataFrame(lst).values.T, index=pd.DataFrame(lst).columns, columns=pd.DataFrame(lst).index).reset_index()json_df.columns=[’numIter’,’eval-auc’,’train-auc’]print(json_df)
看下效果:
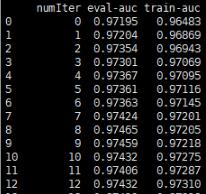
以上這篇獲取python運(yùn)行輸出的數(shù)據(jù)并解析存為dataFrame實(shí)例就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. IntelliJ IDEA設(shè)置默認(rèn)瀏覽器的方法2. 簡(jiǎn)述JAVA同步、異步、阻塞和非阻塞之間的區(qū)別3. Python TestSuite生成測(cè)試報(bào)告過程解析4. 在JSP中使用formatNumber控制要顯示的小數(shù)位數(shù)方法5. SpringBoot項(xiàng)目?jī)?yōu)雅的全局異常處理方式(全網(wǎng)最新)6. docker /var/lib/docker/aufs/mnt 目錄清理方法7. IntelliJ IDEA設(shè)置背景圖片的方法步驟8. 如何清空python的變量9. 解決python路徑錯(cuò)誤,運(yùn)行.py文件,找不到路徑的問題10. python操作數(shù)據(jù)庫獲取結(jié)果之fetchone和fetchall的區(qū)別說明

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備