Python使用urlretrieve實(shí)現(xiàn)直接遠(yuǎn)程下載圖片的示例代碼
在實(shí)現(xiàn)爬蟲任務(wù)時(shí),經(jīng)常需要將一些圖片下載到本地當(dāng)中。那么在python中除了通過open()函數(shù),以二進(jìn)制寫入方式來下載圖片以外,還有什么其他方式嗎?本文將使用urlretrieve實(shí)現(xiàn)直接遠(yuǎn)程下載圖片。
下面我們?cè)賮砜纯?urllib 模塊提供的 urlretrieve() 函數(shù)。urlretrieve() 方法直接將遠(yuǎn)程數(shù)據(jù)下載到本地。
>>> help(urllib.urlretrieve)Help on function urlretrieve in module urllib: urlretrieve(url, filename=None, reporthook=None, data=None)
參數(shù) finename 指定了保存本地路徑(如果參數(shù)未指定,urllib會(huì)生成一個(gè)臨時(shí)文件保存數(shù)據(jù)。)
參數(shù) reporthook 是一個(gè)回調(diào)函數(shù),當(dāng)連接上服務(wù)器、以及相應(yīng)的數(shù)據(jù)塊傳輸完畢時(shí)會(huì)觸發(fā)該回調(diào),我們可以利用這個(gè)回調(diào)函數(shù)來顯示當(dāng)前的下載進(jìn)度。
參數(shù) data 指 post 到服務(wù)器的數(shù)據(jù),該方法返回一個(gè)包含兩個(gè)元素的(filename, headers)元組,filename 表示保存到本地的路徑,header 表示服務(wù)器的響應(yīng)頭。
下面通過例子來演示一下這個(gè)方法的使用,這個(gè)例子將 google 的 html 抓取到本地,保存在 D:/google.html 文件中,同時(shí)顯示下載的進(jìn)度。
import urllibdef cbk(a, b, c): ’’’回調(diào)函數(shù) @a: 已經(jīng)下載的數(shù)據(jù)塊 @b: 數(shù)據(jù)塊的大小 @c: 遠(yuǎn)程文件的大小 ’’’ per = 100.0 * a * b / c if per > 100: per = 100 print ’%.2f%%’ % perurl = ’http://www.google.com’local = ’d://google.html’urllib.urlretrieve(url, local, cbk)
代碼實(shí)現(xiàn)
在python中除了使用open()函數(shù)實(shí)現(xiàn)圖片的下載,還可以通過urllib.request模塊中的urlretrieve實(shí)現(xiàn)直接遠(yuǎn)程下載圖片的操作。以遠(yuǎn)程下載某網(wǎng)頁外設(shè)產(chǎn)品圖片為例,代碼如下:
import requestsimport urllib.requestimport os # 系統(tǒng)模塊import shutil # 文件夾控制def download_pictures(url): headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'} response = requests.get(url, headers=headers) # 發(fā)送網(wǎng)絡(luò)請(qǐng)求 獲取響應(yīng) if response.status_code == 200: # 判斷請(qǐng)求是否成功 # print(response.json()) # 每次獲取數(shù)據(jù)之前,先將保存圖片的文件夾清空 在創(chuàng)建目錄 if os.path.exists('img_download'): # 判斷文件夾是否存在 shutil.rmtree('img_download') # 存在則刪除 os.makedirs('img_download') # 重新創(chuàng)建 else: os.makedirs('img_download') # 不存在 直接創(chuàng)建 content = response.json()['products'] # 獲取響應(yīng)內(nèi)容 print(content) for index, item in enumerate(content): # 圖片地址 img_path = 'http://img13.360buyimg.com/n1/s320x320_' + item['imgPath'] # print(item['imgPath']) # 根據(jù)下標(biāo)命名圖片名稱 urllib.request.urlretrieve(img_path, 'img_download/' + 'img' + str(index) + '.jpg') else: print('請(qǐng)求失敗')if __name__ == ’__main__’: download_pictures('https://ch.jd.com/hotsale2?cateid=686')
運(yùn)行結(jié)果如下圖所示:
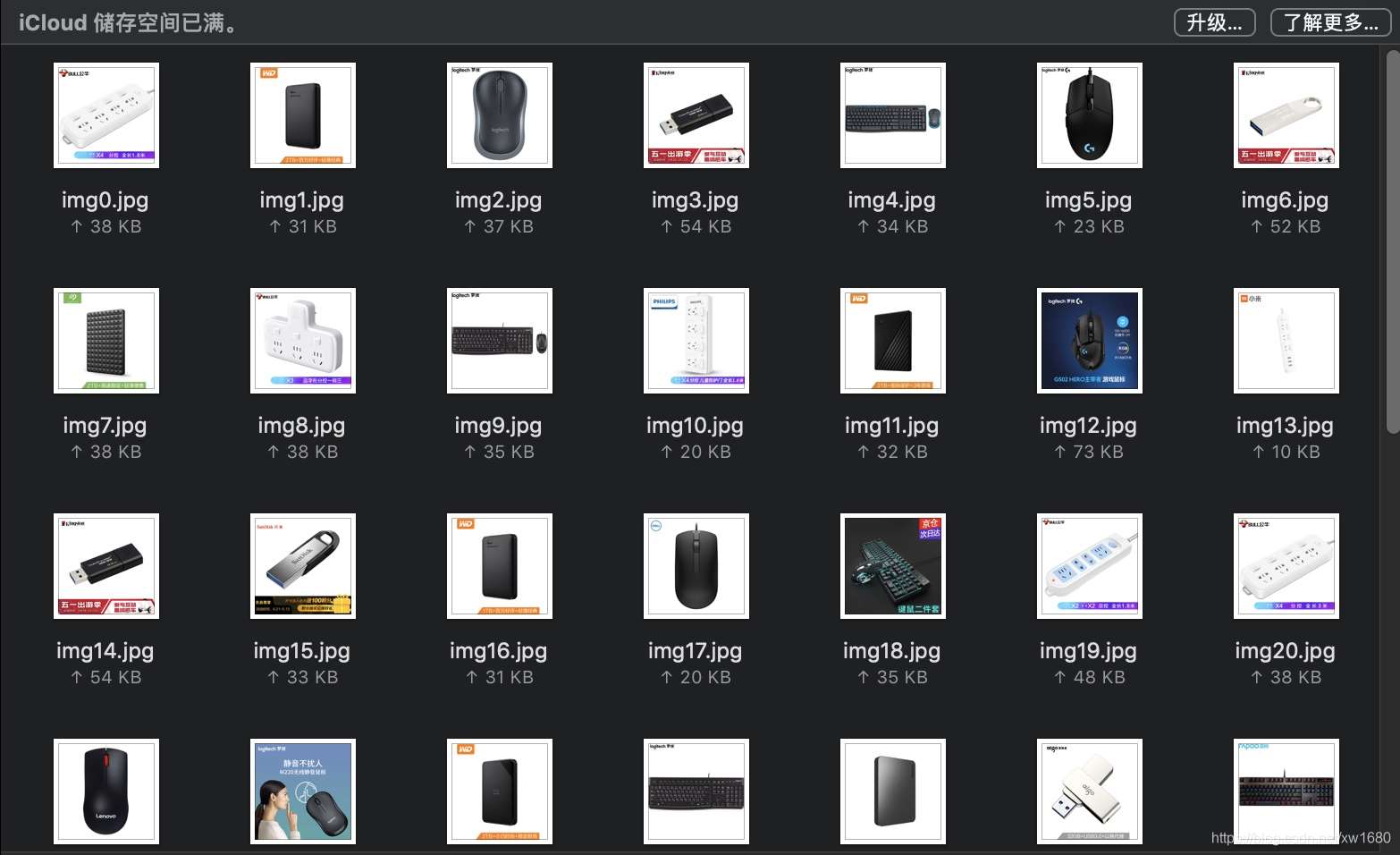
到此這篇關(guān)于Python使用urlretrieve實(shí)現(xiàn)直接遠(yuǎn)程下載圖片的示例代碼的文章就介紹到這了,更多相關(guān)Python urlretrieve遠(yuǎn)程下載內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. python 寫一個(gè)文件分發(fā)小程序2. Python本地及虛擬解釋器配置過程解析3. Python importlib模塊重載使用方法詳解4. Vue3中使用this的詳細(xì)教程5. Python 利用flask搭建一個(gè)共享服務(wù)器的步驟6. Python中Anaconda3 安裝gdal庫的方法7. 用python對(duì)oracle進(jìn)行簡單性能測(cè)試8. Python自動(dòng)化之定位方法大殺器xpath9. Python類綁定方法及非綁定方法實(shí)例解析10. Python Selenium破解滑塊驗(yàn)證碼最新版(GEETEST95%以上通過率)

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備