詳解python中g(shù)roupby函數(shù)通俗易懂
一、groupby 能做什么?
python中g(shù)roupby函數(shù)主要的作用是進(jìn)行數(shù)據(jù)的分組以及分組后地組內(nèi)運(yùn)算!
對(duì)于數(shù)據(jù)的分組和分組運(yùn)算主要是指groupby函數(shù)的應(yīng)用,具體函數(shù)的規(guī)則如下:
df[](指輸出數(shù)據(jù)的結(jié)果屬性名稱(chēng)).groupby([df[屬性],df[屬性])(指分類(lèi)的屬性,數(shù)據(jù)的限定定語(yǔ),可以有多個(gè)).mean()(對(duì)于數(shù)據(jù)的計(jì)算方式——函數(shù)名稱(chēng))
舉例如下:
print(df['評(píng)分'].groupby([df['地區(qū)'],df['類(lèi)型']]).mean())#上面語(yǔ)句的功能是輸出表格所有數(shù)據(jù)中不同地區(qū)不同類(lèi)型的評(píng)分?jǐn)?shù)據(jù)平均值
二、單類(lèi)分組
A.groupby('性別')

首先,我們有一個(gè)變量A,數(shù)據(jù)類(lèi)型是DataFrame
想要按照【性別】進(jìn)行分組
得到的結(jié)果是一個(gè)Groupby對(duì)象,還沒(méi)有進(jìn)行任何的運(yùn)算。
describe()
描述組內(nèi)數(shù)據(jù)的基本統(tǒng)計(jì)量
A.groupby('性別').describe().unstack()
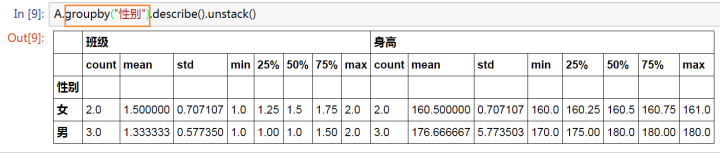
* 只有數(shù)字類(lèi)型的列數(shù)據(jù)才會(huì)計(jì)算統(tǒng)計(jì)
* 示例里面數(shù)字類(lèi)型的數(shù)據(jù)有兩列 【班級(jí)】和【身高】
但是,我們并不需要統(tǒng)計(jì)班級(jí)的均值等信息,只需要【身高】,所以做一下小的改動(dòng):
A.groupby('性別')['身高'].describe().unstack()
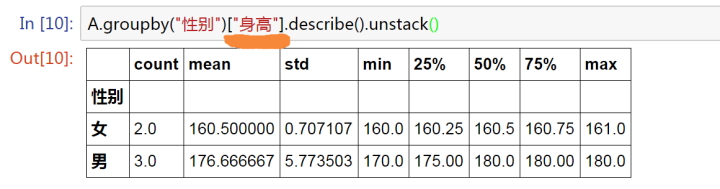
unstack()
索引重排
上面的例子里面用到了一個(gè)小的技巧,讓運(yùn)算結(jié)果更便于對(duì)比查看,感興趣的同學(xué)可以自行去除unstack,比較一下顯示的效果
三、多類(lèi)分組
A.groupby( ['班級(jí)','性別'])
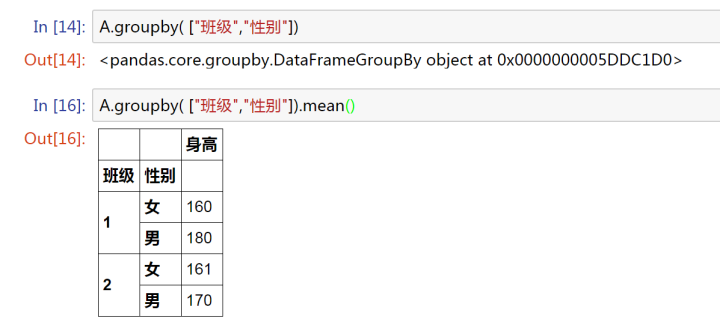
單獨(dú)用groupby,我們得到的還是一個(gè) Groupby 對(duì)象。
mean()
組內(nèi)均值計(jì)算
DataFrame的很多函數(shù)可以直接運(yùn)用到Groupby對(duì)象上。
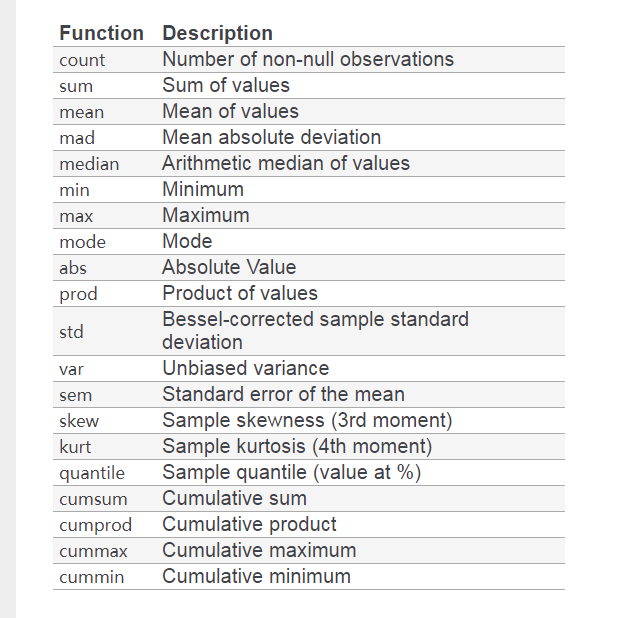
上圖截自 pandas 官網(wǎng) document,這里就不一一細(xì)說(shuō)。
我們還可以一次運(yùn)用多個(gè)函數(shù)計(jì)算
A.groupby( ['班級(jí)','性別']).agg([np.sum, np.mean, np.std]) # 一次計(jì)算了三個(gè)
agg()
分組多個(gè)運(yùn)算
四、時(shí)間分組
時(shí)間序列可以直接作為index,或者有一列是時(shí)間序列,差別不是很大。
這里僅僅演示,某一列為時(shí)間序列。
為A 新增一列【生日】,由于分隔符 “/” 的問(wèn)題,我們查看列屬性,【生日】的屬性并不是日期類(lèi)型
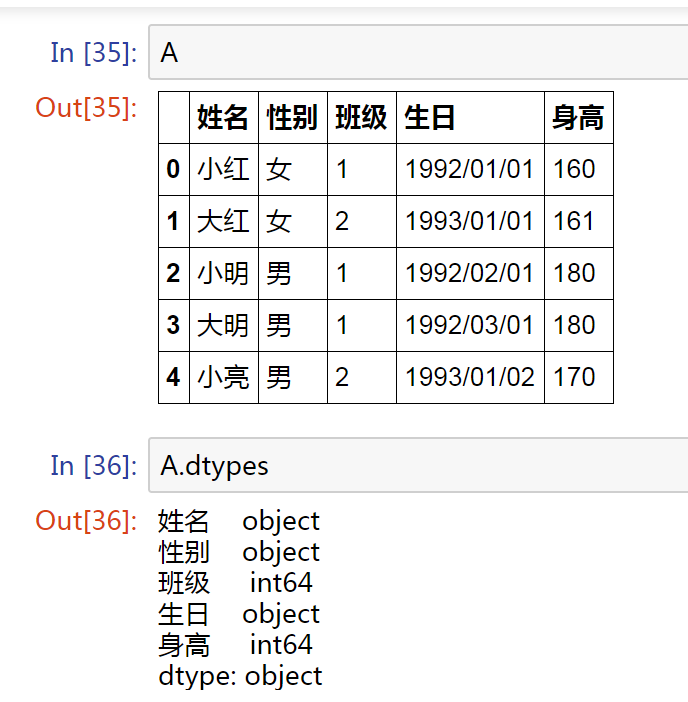
我們想做的是:
1、按照【生日】的【年份】進(jìn)行分組,看看有多少人是同齡?
A['生日'] = pd.to_datetime(A['生日'],format ='%Y/%m/%d') # 轉(zhuǎn)化為時(shí)間格式A.groupby(A['生日'].apply(lambda x:x.year)).count() # 按照【生日】的【年份】分組
進(jìn)一步,我們想選拔:
2、同一年作為一個(gè)小組,小組內(nèi)生日靠前的那一位作為小隊(duì)長(zhǎng):
A.sort_values('生日', inplace=True) # 按時(shí)間排序A.groupby(A['生日'].apply(lambda x:x.year),as_index=False).first()

as_index=False
保持原來(lái)的數(shù)據(jù)索引結(jié)果不變
first()
保留第一個(gè)數(shù)據(jù)
Tail(n=1)
保留最后n個(gè)數(shù)據(jù)
再進(jìn)一步:
3、想要找到哪個(gè)月只有一個(gè)人過(guò)生日
A.groupby(A['生日'].apply(lambda x:x.month),as_index=False) # 到這里是按月分組A.groupby(A['生日'].apply(lambda x:x.month),as_index=False).filter(lambda x: len(x)==1)
filter()
對(duì)分組進(jìn)行過(guò)濾,保留滿(mǎn)足()條件的分組
以上就是 groupby 最經(jīng)常用到的功能了。
用 first(),tail()截取每組前后幾個(gè)數(shù)據(jù)
用 apply()對(duì)每組進(jìn)行(自定義)函數(shù)運(yùn)算
用 filter()選取滿(mǎn)足特定條件的分組
到此這篇關(guān)于詳解python中g(shù)roupby函數(shù)通俗易懂的文章就介紹到這了,更多相關(guān)python groupby函數(shù)內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Python的Tqdm模塊實(shí)現(xiàn)進(jìn)度條配置2. react axios 跨域訪問(wèn)一個(gè)或多個(gè)域名問(wèn)題3. WML語(yǔ)言的基本情況4. CSS代碼檢查工具stylelint的使用方法詳解5. 利用CSS制作3D動(dòng)畫(huà)6. Python 多線程之threading 模塊的使用7. 刪除docker里建立容器的操作方法8. .NET6打包部署到Windows Service的全過(guò)程9. ThinkPHP5 通過(guò)ajax插入圖片并實(shí)時(shí)顯示(完整代碼)10. Properties 持久的屬性集的實(shí)例詳解

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備