Python基于pandas爬取網頁表格數據
以網頁表格為例:https://www.kuaidaili.com/free/
該網站數據存在table標簽,直接用requests,需要結合bs4解析正則/xpath/lxml等,沒有幾行代碼是搞不定的。
今天介紹的黑科技是pandas自帶爬蟲功能,pd.read_html(),只需傳人url,一行代碼搞定。
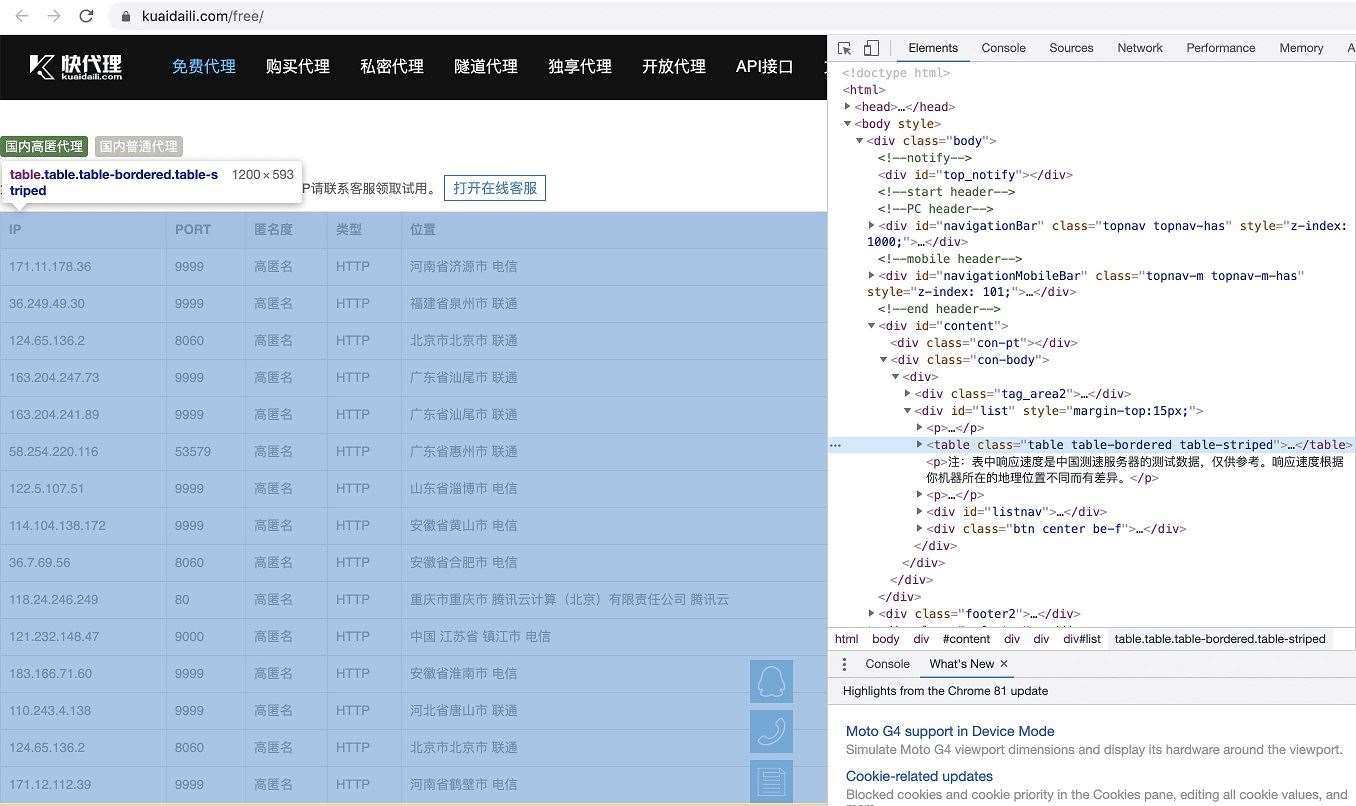
原網頁結構如下:
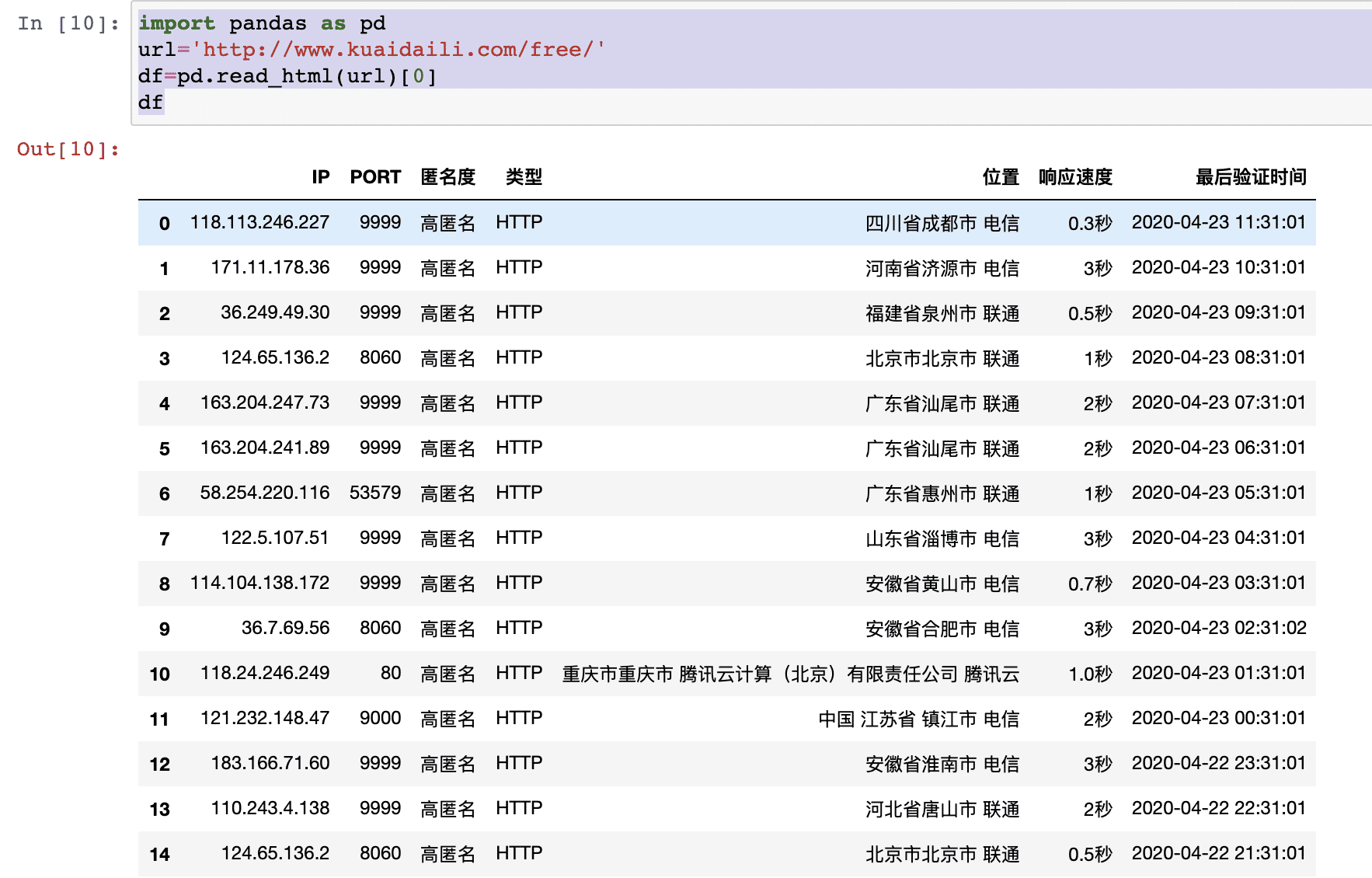
python代碼如下:
import pandas as pdurl=’http://www.kuaidaili.com/free/’df=pd.read_html(url)[0] # [0]:表示第一個table,多個table需要指定,如果不指定默認第一個# 如果沒有【0】,輸入dataframe格式組成的listdf
輸出dataframe格式數據

再次保存到本地,csv格式,注意中文編碼:utf_8_sig
print(type(df))df.to_csv(’free ip.csv’,mode=’a’, encoding=’utf_8_sig’, header=1, index=0)print(’done!’)
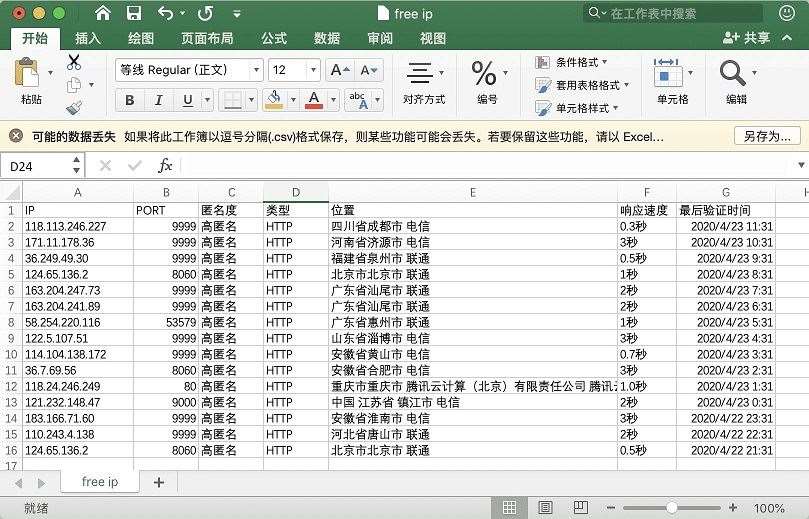
查看csv文件
先來了解一下read_html函數的api:
pandas.read_html(io, match=’.+’, flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None, thousands=’, ’, encoding=None, decimal=’.’, converters=None, na_values=None, keep_default_na=True, displayed_only=True)
常用的參數:
io:可以是url、html文本、本地文件等; flavor:解析器; header:標題行; skiprows:跳過的行; attrs:屬性,比如 attrs = {’id’: ’table’}; parse_dates:解析日期注意:返回的結果是**DataFrame**組成的**list**。
若要dataframe,直接取list【0】
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備