python解析xml文件方式(解析、更新、寫入)
Overview
這篇博客內容將包括對XML文件的解析、追加新元素后寫入到XML,以及更新原XML文件中某結點的值。使用的是python的xml.dom.minidom包,詳情可見其官方文檔:xml.dom.minidom官方文檔。全文都將圍繞以下的customer.xml進行操作:
<?xml version='1.0' encoding='utf-8' ?><!-- This is list of customers --><customers> <customer ID='C001'> <name>Acme Inc.</name> <phone>12345</phone> <comments> <![CDATA[Regular customer since 1995]]> </comments> </customer> <customer ID='C002'> <name>Star Wars Inc.</name> <phone>23456</phone> <comments> <![CDATA[A small but healthy company.]]> </comments> </customer></customers>
CDATA:在XML中,不會被解析器解析的部分數據。
聲明:在本文中,結點和節點被視為了同一個概念,你可以在全文的任何地方替換它,我個人感覺區別不是很大,當然,你也可以看做是我的打字輸入錯誤。
1. 解析XML文件
在解析XML時,所有的文本都是儲存在文本節點中的,且該文本節點被視為元素結點的子結點,例如:2005,元素節點 ,擁有一個值為 “2005” 的文本節點,“2005” 不是 元素的值,最常用的方法就是getElementsByTagName()方法了,獲取到結點后再進一步根據文檔結構解析即可。
具體的理論就不過多描述,配合上述XML文件和下面的代碼,你將清楚的看到操作方法,下面的代碼執行的工作是將所有的結點名稱以及結點信息輸出一下:
# -*- coding: utf-8 -*-''' @Author : LiuZhian @Time : 2019/4/24 0024 上午 9:19 @Comment : '''from xml.dom.minidom import parsedef readXML(): domTree = parse('./customer.xml') # 文檔根元素 rootNode = domTree.documentElement print(rootNode.nodeName) # 所有顧客 customers = rootNode.getElementsByTagName('customer') print('****所有顧客信息****') for customer in customers: if customer.hasAttribute('ID'): print('ID:', customer.getAttribute('ID')) # name 元素 name = customer.getElementsByTagName('name')[0] print(name.nodeName, ':', name.childNodes[0].data) # phone 元素 phone = customer.getElementsByTagName('phone')[0] print(phone.nodeName, ':', phone.childNodes[0].data) # comments 元素 comments = customer.getElementsByTagName('comments')[0] print(comments.nodeName, ':', comments.childNodes[0].data)if __name__ == ’__main__’: readXML()

2. 寫入XML文件
在寫入時,我覺得可分為兩種方式:
新建一個全新的XML文件
在已有XML文件基礎上追加一些元素信息
至于以上兩種情況,其實創建元素結點的方法類似,你必須要做的都是先創建/得到一個DOM對象,再在DOM基礎上創建new一個新的結點。
如果是第一種情況,你可以通過dom=minidom.Document()來創建;如果是第二種情況,直接可以通過解析已有XML文件來得到dom對象,例如dom = parse('./customer.xml')
在具體創建元素/文本結點時,你大致會寫出像以下這樣的“四部曲”代碼:
①創建一個新元素結點createElement()
②創建一個文本節點createTextNode()
③將文本節點掛載元素結點上
④將元素結點掛載到其父元素上。
現在,我需要新建一個customer節點,信息如下:
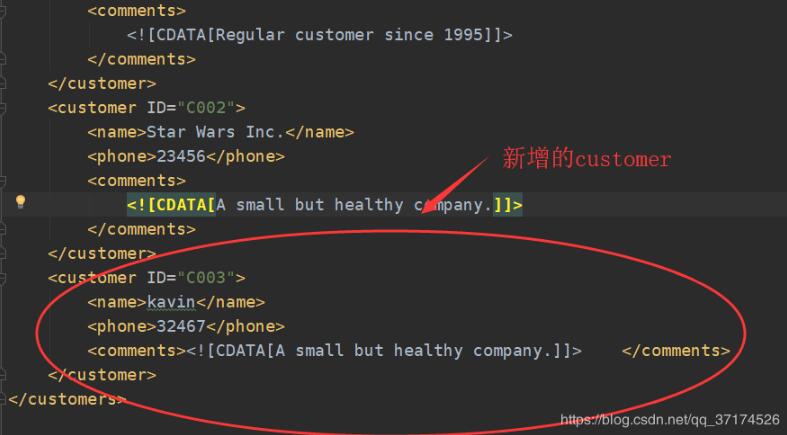
<customer ID='C003'> <name>kavin</name> <phone>32467</phone> <comments> <![CDATA[A small but healthy company.]]> </comments> </customer>
代碼如下:
def writeXML(): domTree = parse('./customer.xml') # 文檔根元素 rootNode = domTree.documentElement # 新建一個customer節點 customer_node = domTree.createElement('customer') customer_node.setAttribute('ID', 'C003') # 創建name節點,并設置textValue name_node = domTree.createElement('name') name_text_value = domTree.createTextNode('kavin') name_node.appendChild(name_text_value) # 把文本節點掛到name_node節點 customer_node.appendChild(name_node) # 創建phone節點,并設置textValue phone_node = domTree.createElement('phone') phone_text_value = domTree.createTextNode('32467') phone_node.appendChild(phone_text_value) # 把文本節點掛到name_node節點 customer_node.appendChild(phone_node) # 創建comments節點,這里是CDATA comments_node = domTree.createElement('comments') cdata_text_value = domTree.createCDATASection('A small but healthy company.') comments_node.appendChild(cdata_text_value) customer_node.appendChild(comments_node) rootNode.appendChild(customer_node) with open(’added_customer.xml’, ’w’) as f: # 縮進 - 換行 - 編碼 domTree.writexml(f, addindent=’ ’, encoding=’utf-8’)if __name__ == ’__main__’: writeXML()
3. 更新XML文件
在更新XML時,只需先找到對應的元素結點,然后將其下的文本結點或屬性取值更新即可,然后保存到文件,具體我就不多說了,代碼中我將思路都注釋清楚了,如下:
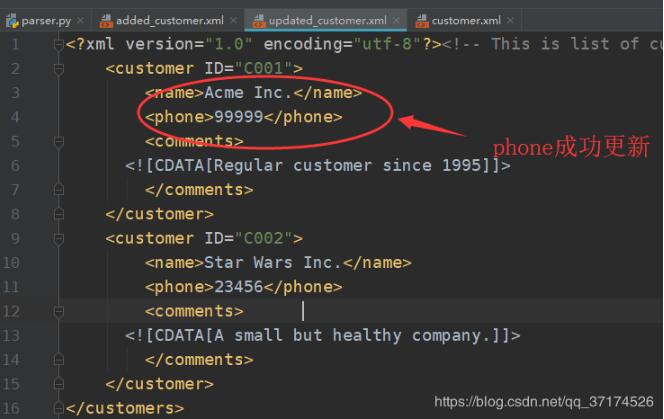
def updateXML(): domTree = parse('./customer.xml') # 文檔根元素 rootNode = domTree.documentElement names = rootNode.getElementsByTagName('name') for name in names: if name.childNodes[0].data == 'Acme Inc.': # 獲取到name節點的父節點 pn = name.parentNode # 父節點的phone節點,其實也就是name的兄弟節點 # 可能有sibNode方法,我沒試過,大家可以google一下 phone = pn.getElementsByTagName('phone')[0] # 更新phone的取值 phone.childNodes[0].data = 99999 with open(’updated_customer.xml’, ’w’) as f: # 縮進 - 換行 - 編碼 domTree.writexml(f, addindent=’ ’, encoding=’utf-8’)if __name__ == ’__main__’: updateXML()
如有不對之處,還煩請指教~
補充知識:python 讀取xml文件內容并完成修改
我就廢話不多說了,還是直接看代碼吧!
import osimport xml.etree.ElementTree as ETdef changesku(inputpath): listdir = os.listdir(inputpath) for file in listdir: if file.endswith(’xml’): file = os.path.join(inputpath,file) tree = ET.parse(file) root = tree.getroot() for object1 in root.findall(’object’): #我要修改的元素在object里面,所以需要先找到objectfor sku in object1.findall(’name’): #查找想要修改的所有同種元素 if (sku.text == ’005’): #‘005’為原始的text sku.text = ’008’ #修改‘name’的標簽值 tree.write(file,encoding=’utf-8’) #寫進原始的xml文件,不然修改就無效,‘encoding = “utf - 8”’避免原始xml #中文字符亂碼 else: pass else: passif __name__ == ’__main__’: inputpath = ’D:easyhebing_xml’ #這是xml文件的文件夾的絕對地址 changesku(inputpath)
以上這篇python解析xml文件方式(解析、更新、寫入)就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備